


据 NVIDIA 技术博客报道,NVIDIA NeMo 推出了其最新的文本转语音 (TTS) 技术创新,即 T5-TTS 型号。这种新模型代表了该领域的重大进步,它利用大型语言模型 (LLM) 来生成更准确、更自然的语音。
LLM 在语音合成中的作用
LLM 凭借其理解和生成连贯文本的能力彻底改变了自然语言处理 (NLP)。最近,这些模型已经适用于语音领域,捕捉了人类语音模式和语调的细微差别。这种适应导致了语音合成模型,可以产生更自然和富有表现力的语音,为各种应用开辟了新的可能性。
Related articles


然而,与它们在文本处理中的使用类似,语音合成中的LLM也面临着幻觉的挑战,这可能会阻碍现实世界的部署。
T5-TTS模型概述
T5-TTS 模型利用编码器-解码器转换器架构进行语音合成。编码器处理文本输入,而自动回归解码器则从目标说话人那里获取参考语音提示以生成语音标记。这些令牌是通过转换器的交叉注意力头来关注编码器的输出而创建的,转换器的交叉注意力头学习对齐文本和语音。尽管它们很健壮,但这些头可能会动摇,尤其是当输入文本包含重复的单词时。
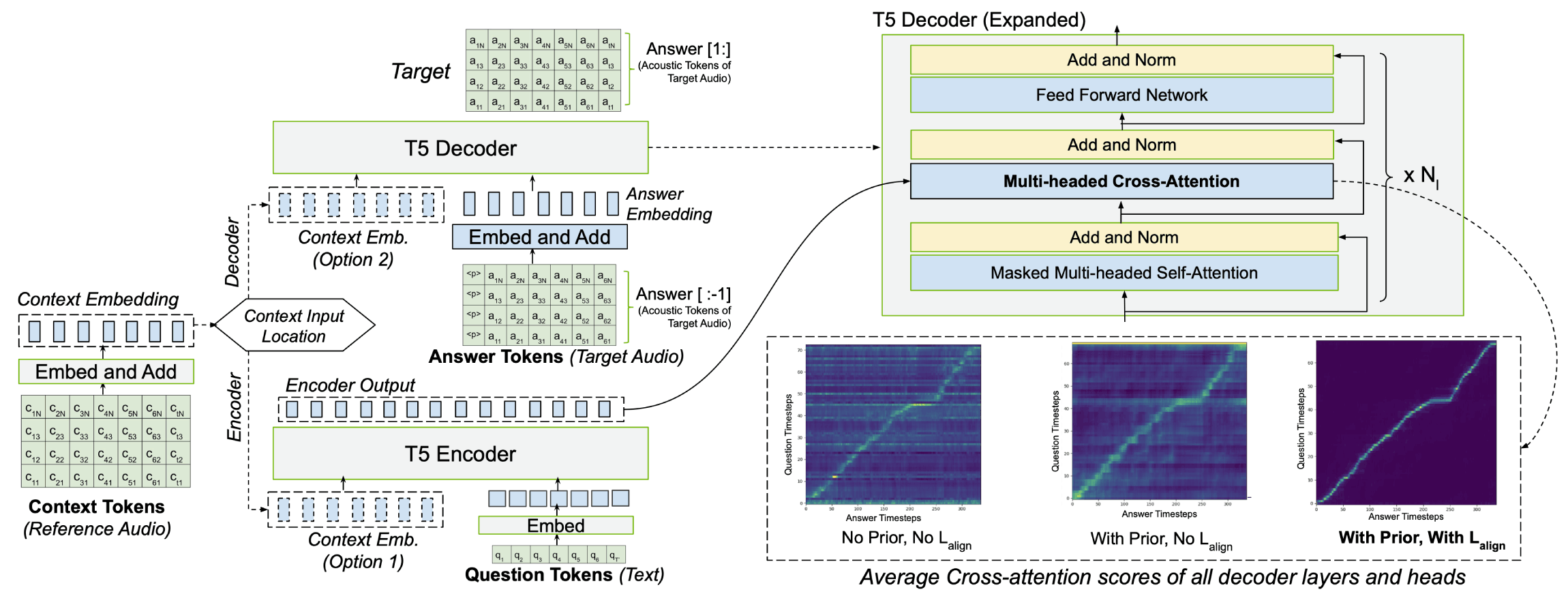
应对幻觉挑战
当生成的语音偏离预期文本时,就会发生 TTS 中的幻觉,导致从轻微发音错误到完全不正确的单词等错误。这些不准确可能会影响 TTS 系统在辅助技术、客户服务和内容创建等关键应用中的可靠性。
T5-TTS 模型通过更有效地将文本输入与相应的语音输出对齐来解决这个问题,从而显着减少幻觉。通过应用单调对齐先验和连接主义时间分类 (CTC) 损失,生成的语音与预期文本紧密匹配,从而产生更可靠、更准确的 TTS 系统。对于单词发音,与 Bark 相比,T5-TTS 模型的错误减少了 2 倍,与 VALLE-X 相比减少了 1.8 倍的错误,与 SpeechT5 相比减少了 1.5 倍的错误。
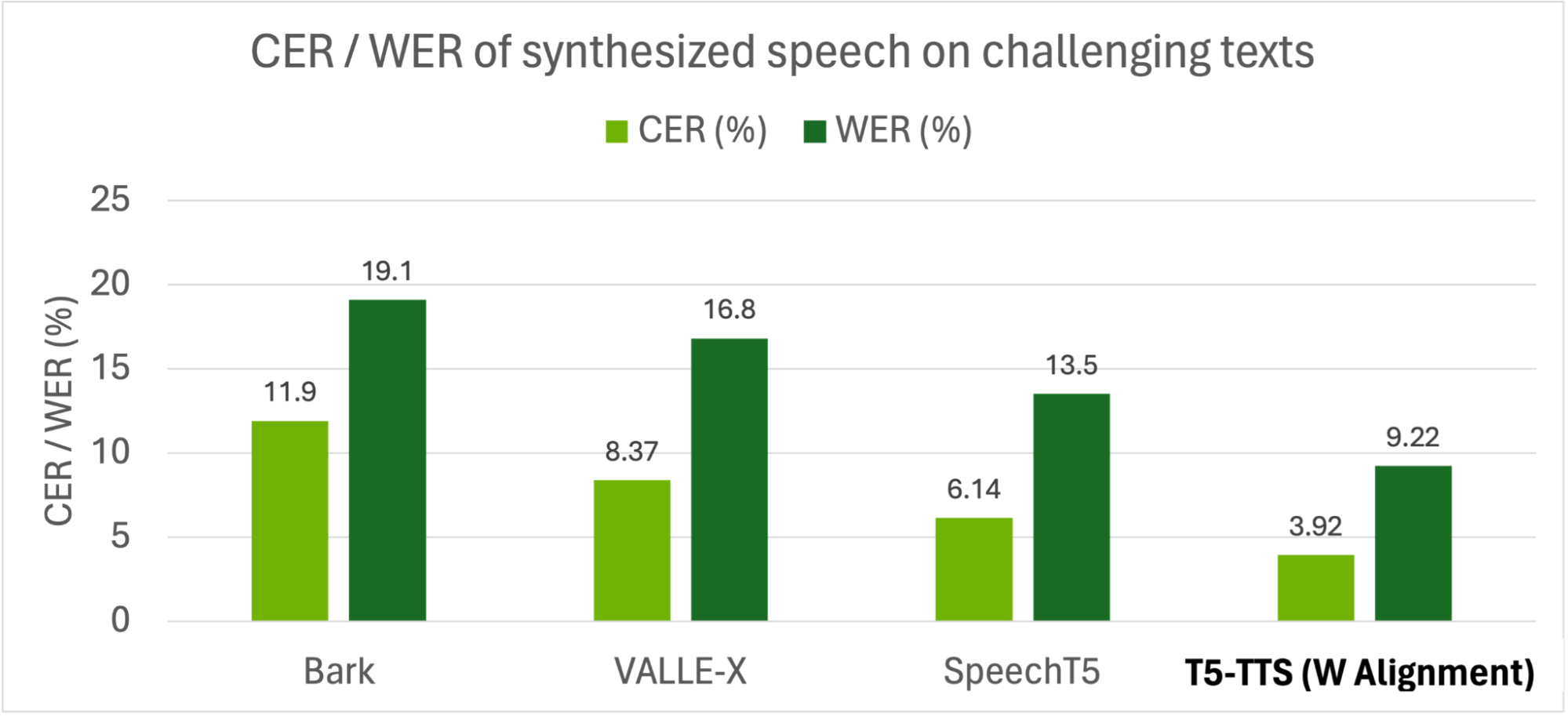
启示与未来研究
NVIDIA NeMo 发布的 T5-TTS 型号标志着 TTS 系统的重大进步。通过有效解决幻觉问题,该模型为更可靠和高质量的语音合成奠定了基础,增强了各种应用的用户体验。
展望未来,NVIDIA NeMo 团队计划通过扩展语言支持、提高其捕获不同语音模式的能力以及将其集成到更广泛的 NLP 框架中来进一步完善 T5-TTS 模型。
探索 NVIDIA NeMo T5-TTS 型号
T5-TTS模型代表了实现更准确、更自然的文本到语音合成的重大突破。其学习稳健文本和语音对齐的创新方法为该领域树立了新的标杆,有望改变我们与 TTS 技术互动并从中受益的方式。
要访问 T5-TTS 模型并开始探索其潜力,请访问 GitHub 上的 NVIDIA/NeMo。无论您是研究人员、开发人员还是发烧友,这款强大的工具都为文本转语音技术领域的创新和进步提供了无数的可能性。若要了解详细信息,请参阅通过学习单调对齐来提高基于 LLM 的语音合成的鲁棒性。
确认
我们感谢所有为这项工作做出贡献的模型作者和合作者,包括 Paarth Neekhara、Shehzeen Hussain、Subhankar Ghosh、Jason Li、Boris Ginsburg、Rafael Valle 和 Rohan Badlani。
图片来源:Shutterstock
















{kind=link}